
Import data từ Google Drive
Tài liệu hướng dẫn bạn nắm thao tác cách import một danh sách các files từ 1 tệp có trên Google Drive vào hệ thống PangoCDP.
Bước 1: Tạo một kết nối đến Google Drive
Bước 2: Tạo 1 dataset
2.1/ Tạo một Dataset trên PangoCDP theo các bước:










Mapping những trường data tương ứng giữa file và model bằng cách chọn icon


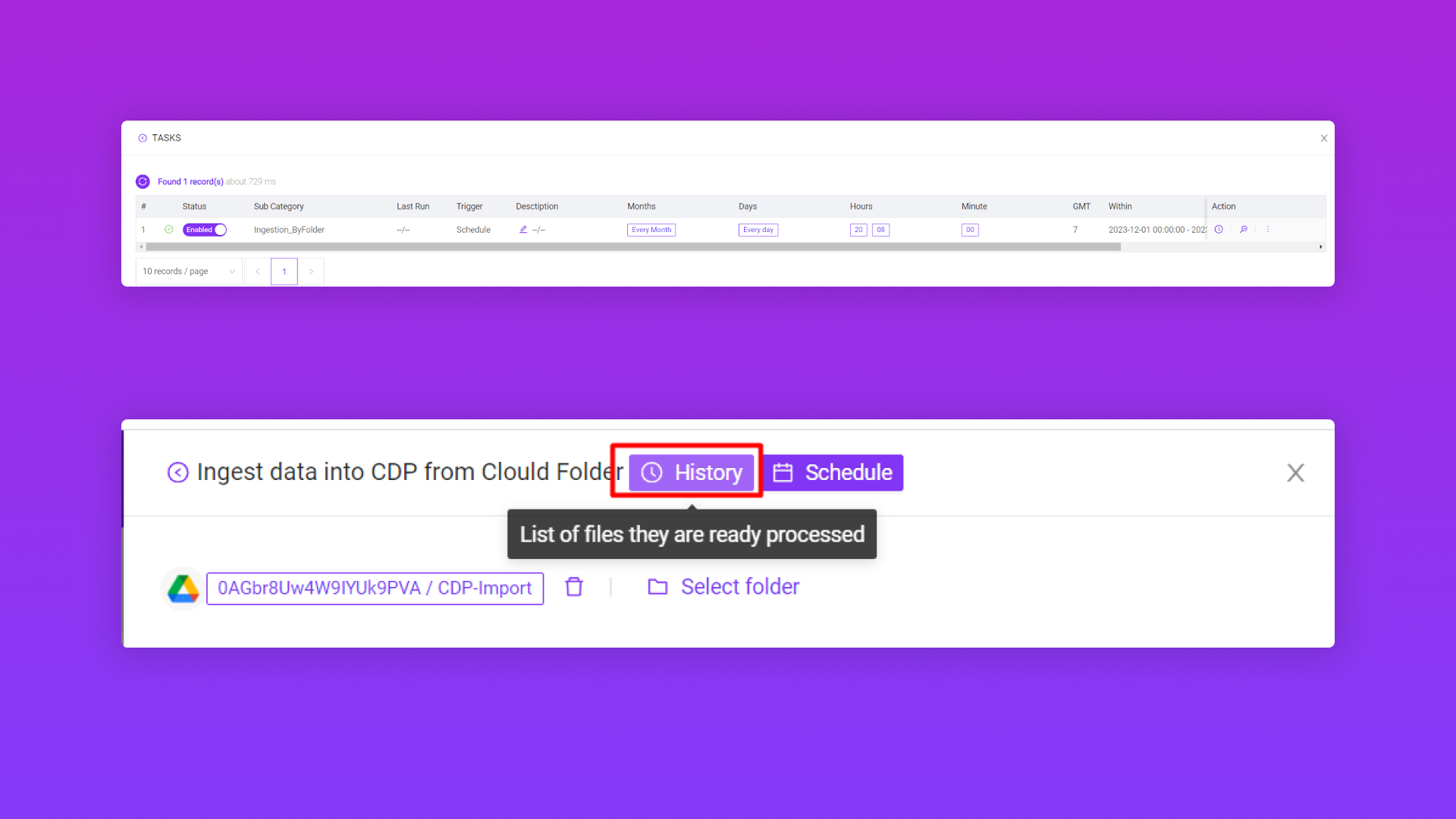
2.2/ Ingest data vào Pango CDP từ Clould Folder (Google Drive)
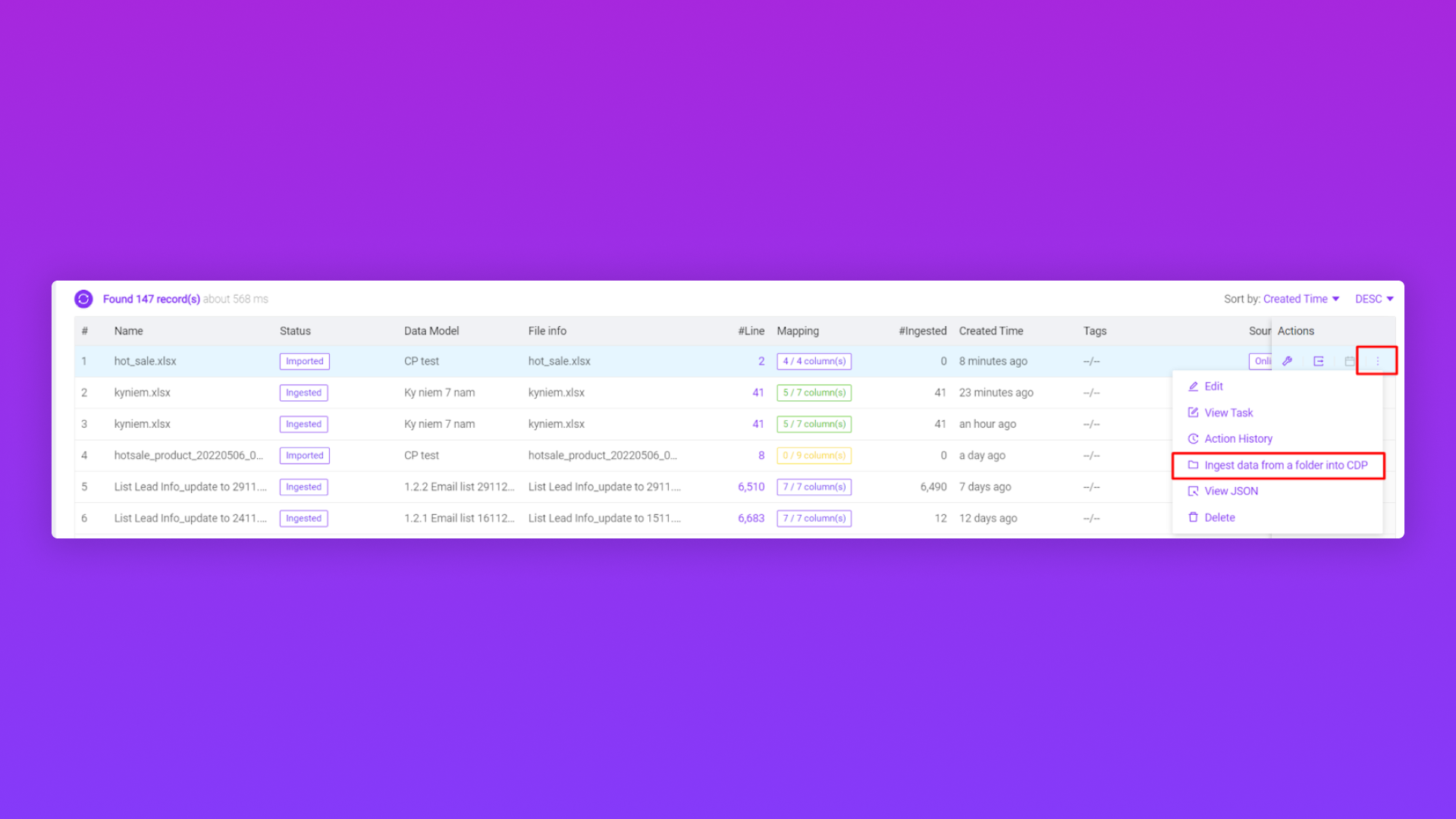

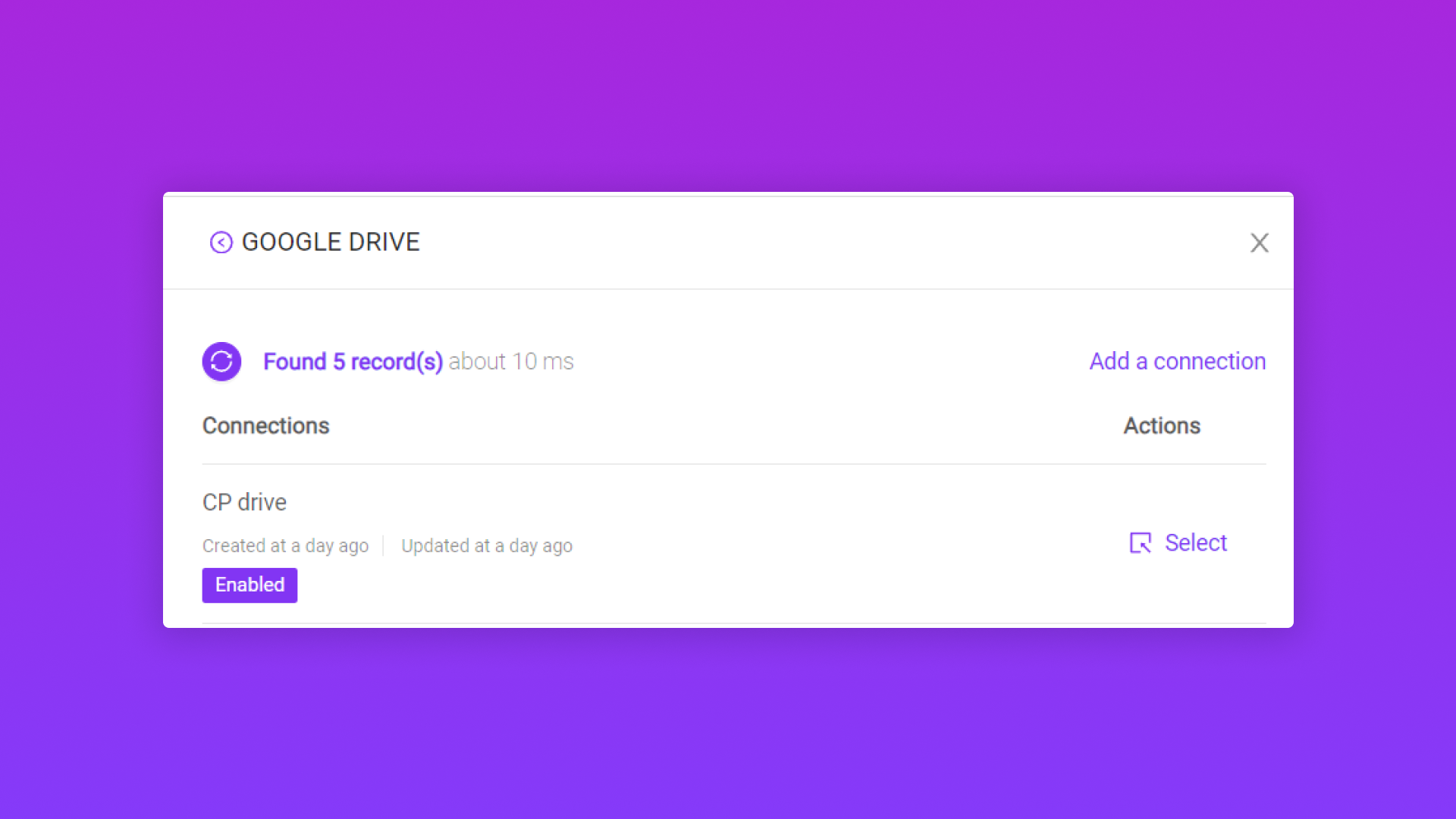
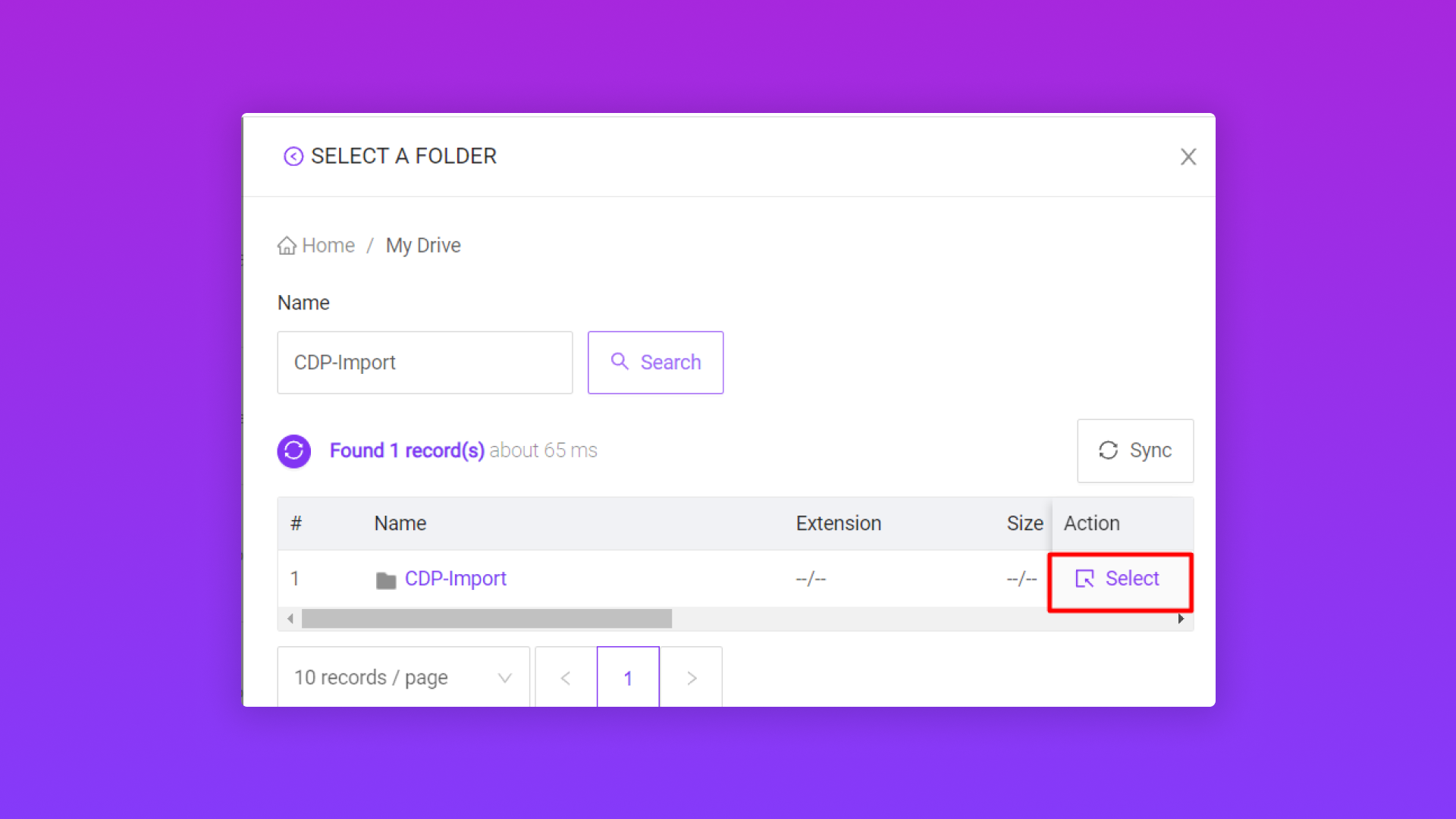
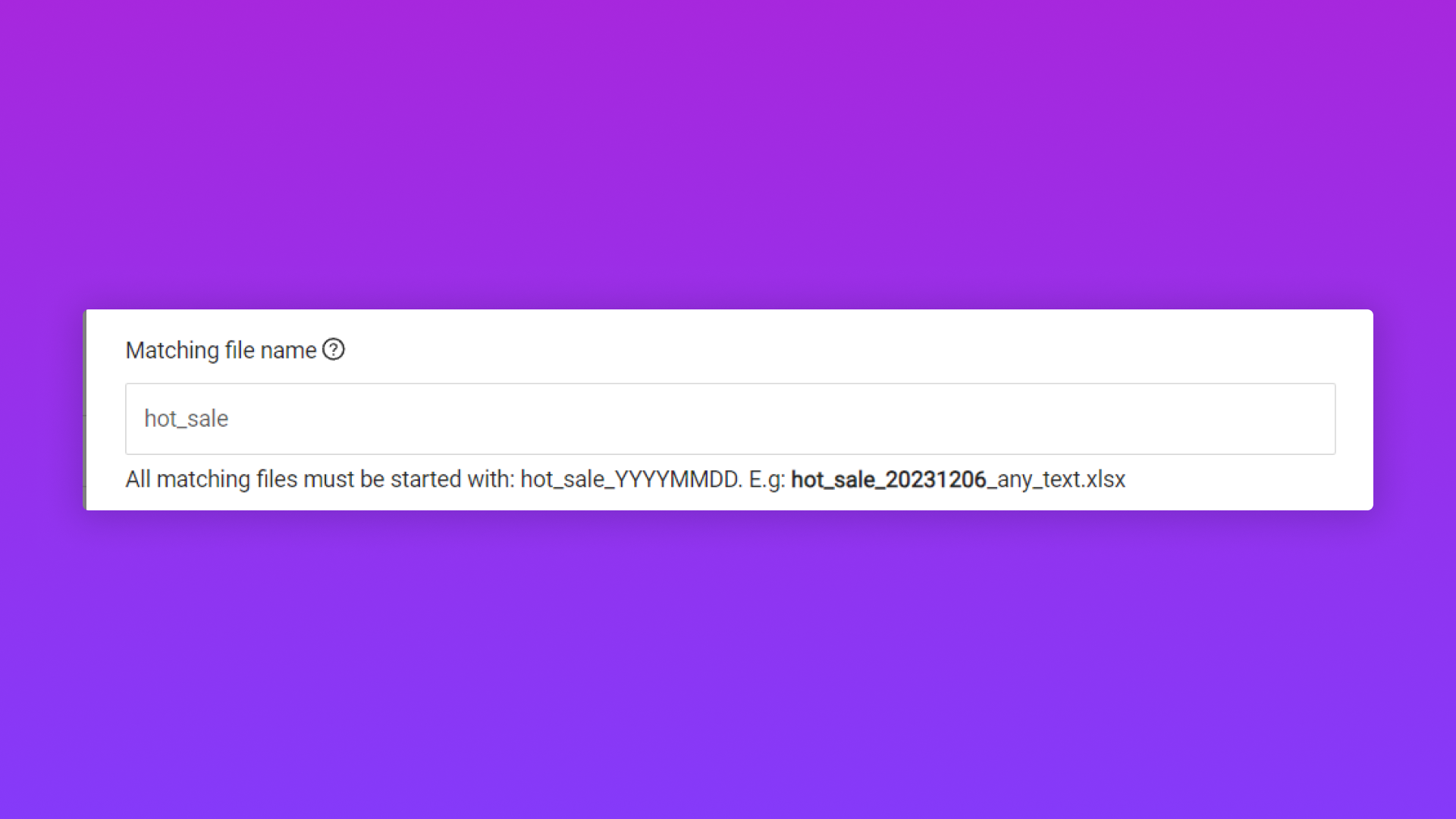
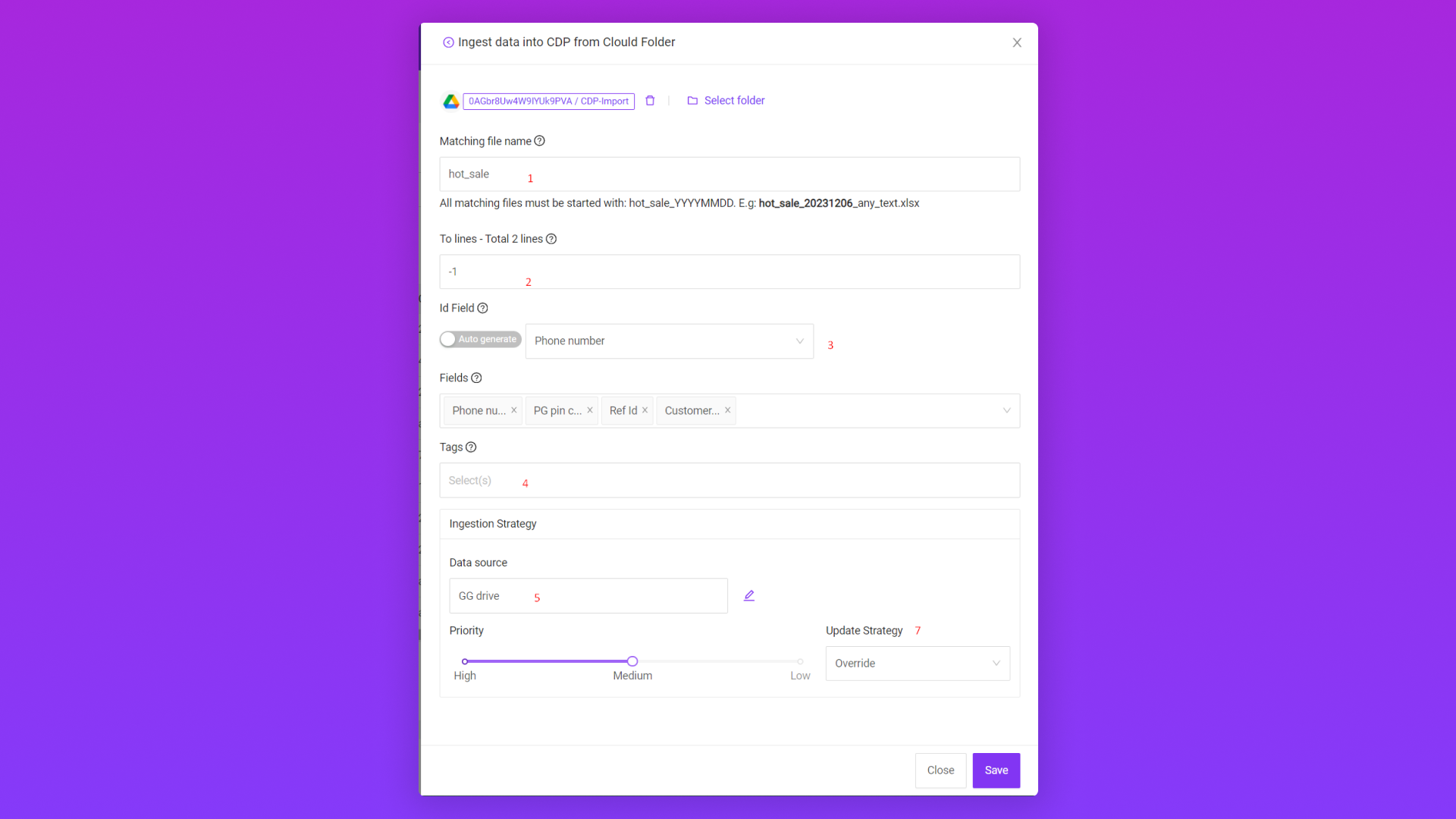
Trường thông tin
Ý nghĩa
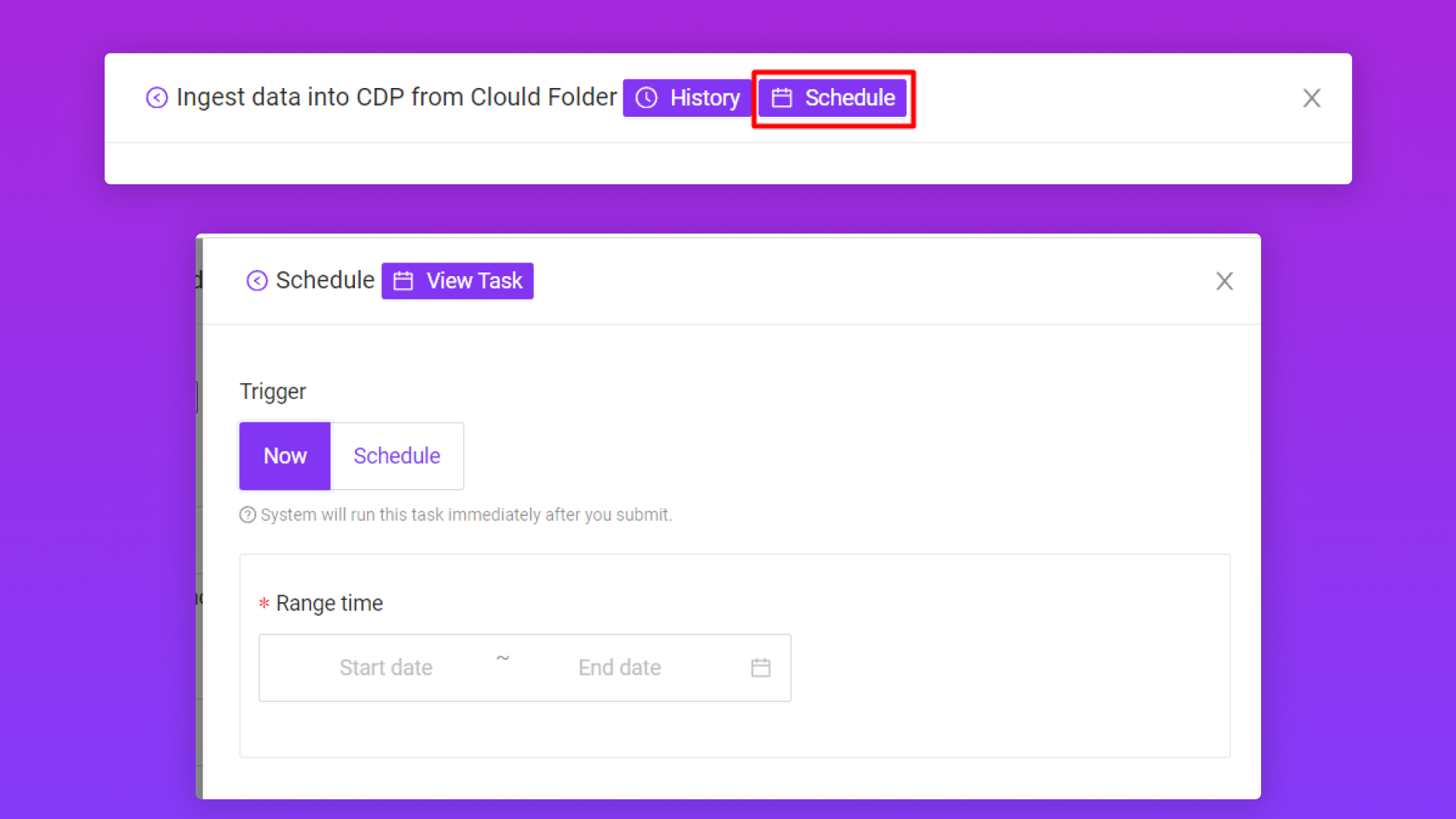
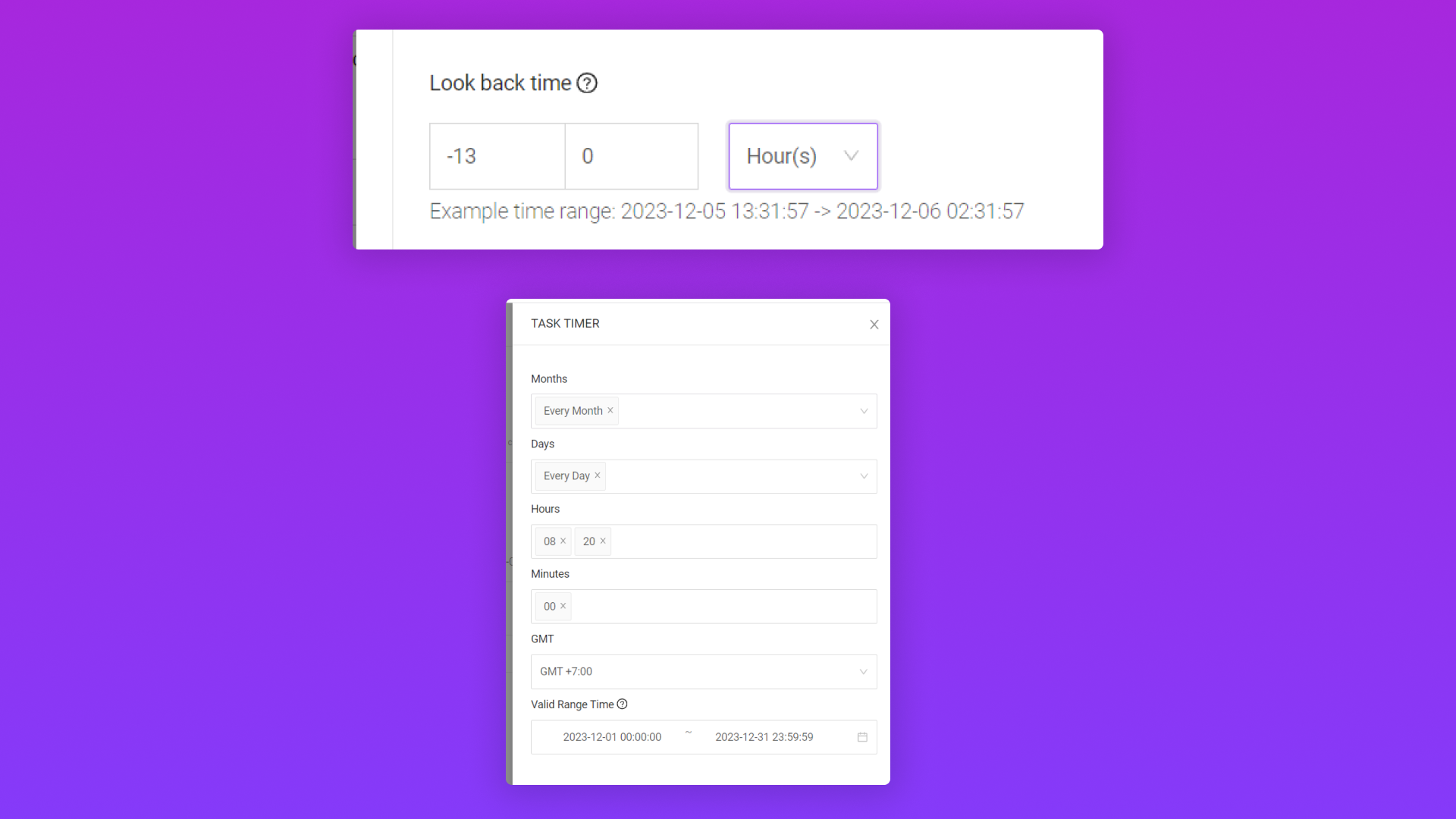
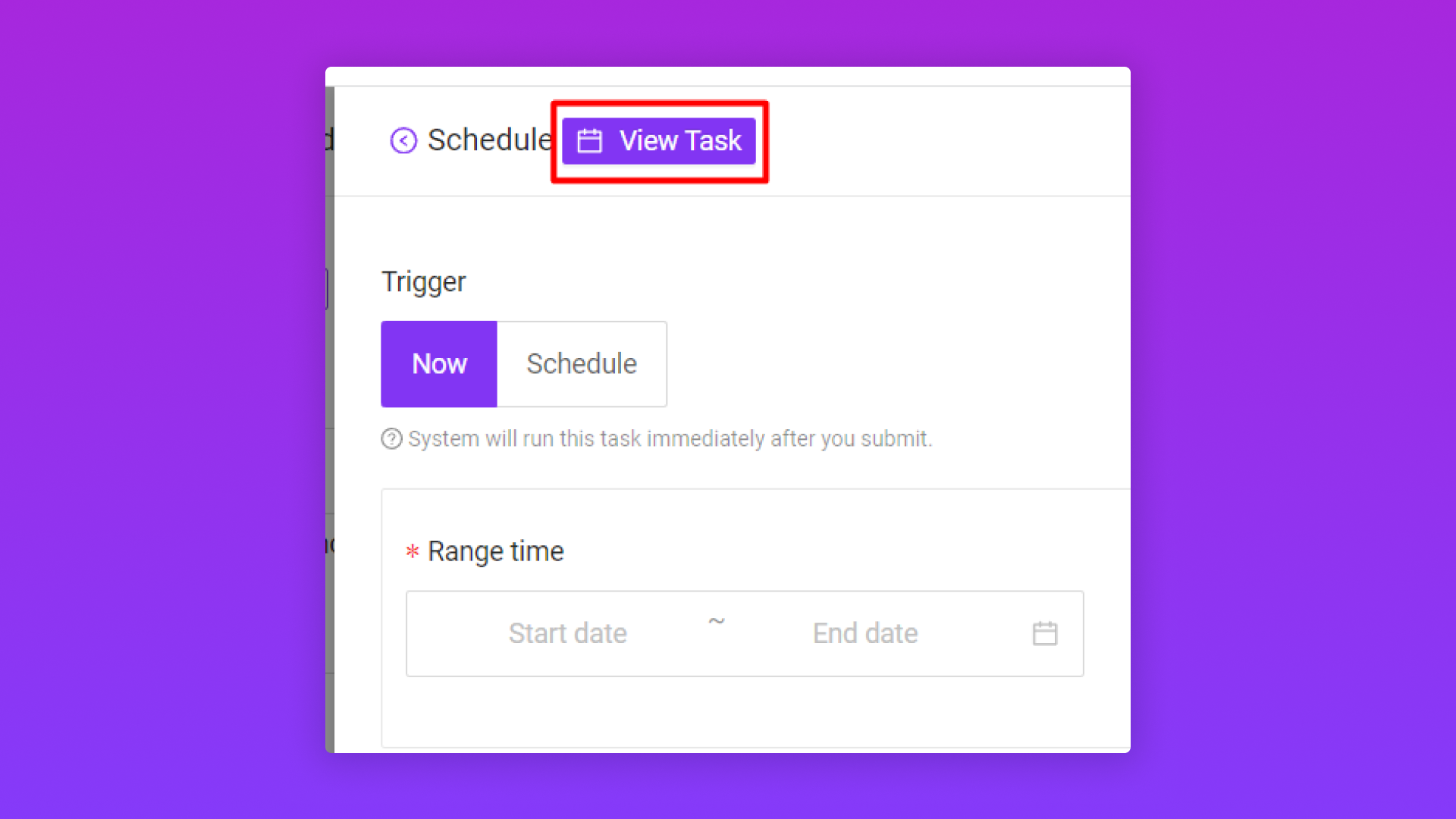
2.3/ Kiểm tra và xem lại file dữ liệu đã sync
Last updated
Was this helpful?